

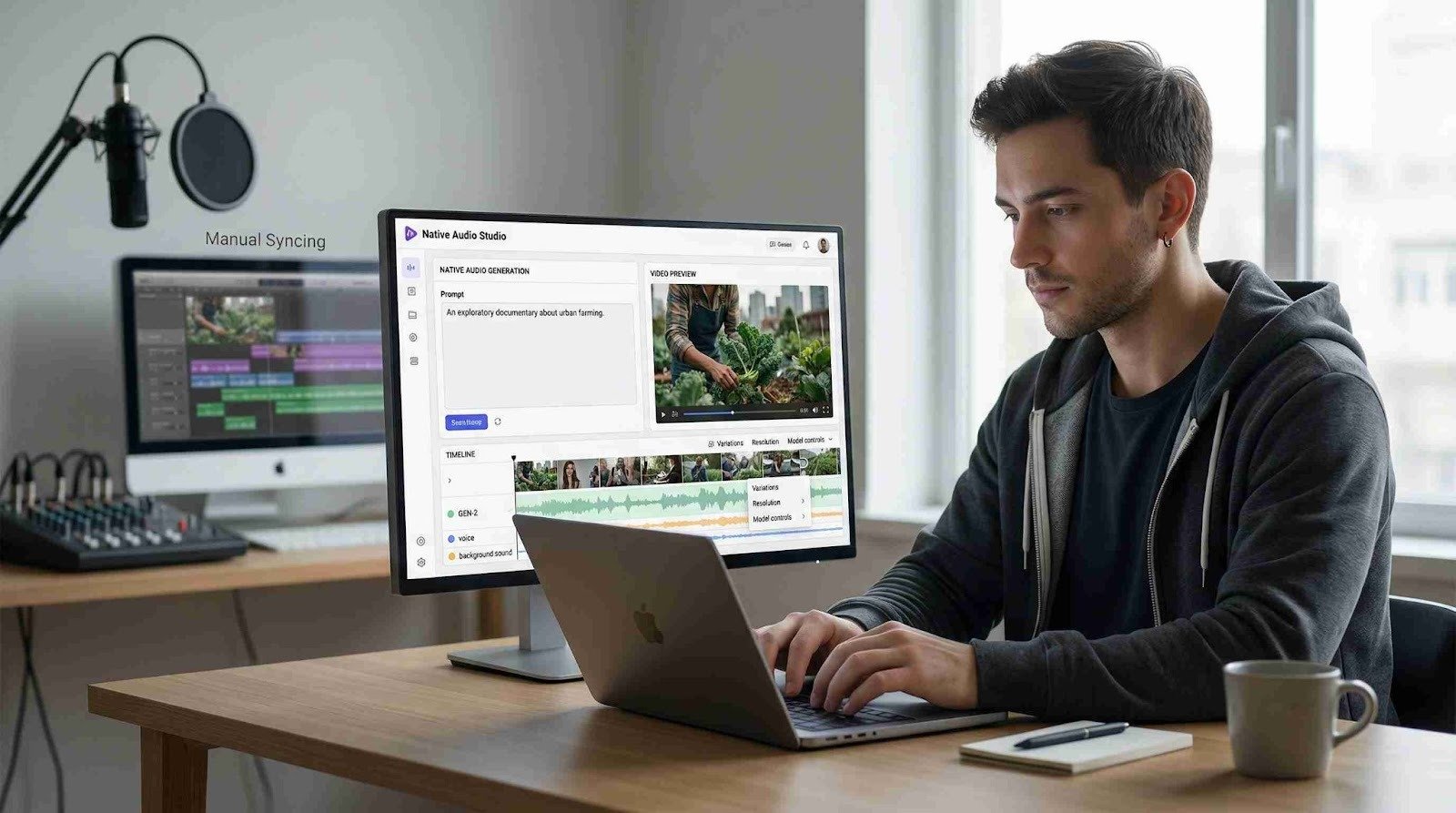
In 2026, the arrival of native audio has officially ended the silent film era of generative AI. For years, creators had to hunt for sound effects and manually align voiceovers in post-production, but the new standard is simultaneous generation.
Native audio means the AI no longer simply adds sound to a finished clip. Instead, models like Seedance 2.0 on the Higgsfield platform generate audio and video together in a single mathematical pass. This shift from fragmented tools to a unified multimodal architecture is fundamentally changing how content is produced.
The core problem with previous generations of AI video was the lack of sensory cohesion. You could produce a visually stunning shot of a car speeding through a desert, but the engine roar was often a generic stock sound effect layered on later. Native audio solves this by ensuring that every visual action is born with its corresponding acoustic property.
The Death of the Post-Production Bottleneck
In the past, a high-end 15-second ad required a visual artist, a sound designer, and an editor. Native audio collapses these roles into a single step. This efficiency is not just about saving time; it is about enabling a new kind of rapid-fire creativity.
- Instant Sync: You no longer have to slide audio clips to match a door slam or a footstep. The AI hears the motion it creates as it renders the pixels. If a character drops a glass, the shatter happens at the exact frame of impact.
- Contextual Soundscapes: If a scene is set in a rainy city, the model automatically generates the specific patter of rain on metal and the distant hum of traffic. It understands the difference between rain hitting a tin roof versus rain hitting a puddle.
- Zero-Drift Dialogue: Because speech is generated with the lip movements, the audio never falls out of sync, even in complex 4K renders. This eliminates the rubber-band effect often seen in early AI video dubbing.
By removing the friction of manual alignment, Higgsfield allows creators to focus on the narrative arc rather than the technical timeline. This democratization of production means that a solo entrepreneur can now compete with an entire marketing agency.
From Silent Puppets to Living Characters
Native audio moves us past the era of static AI avatars. When sound is generated natively, it is physically grounded in the character’s performance. This creates a sense of presence that makes AI characters feel like living beings rather than digital puppets.
- Acoustic Physics: The sound changes based on the environment. A character speaking in a cathedral will have a natural reverb that matches the visual architecture. The AI understands that the material of the walls and the height of the ceiling dictate how sound waves should bounce.
- Biological Realism: Shouting or whispering is more than just a volume change. The model adjusts facial tension and neck muscles to match the vocal strain. If a character whispers a secret, their entire facial structure softens to match the intimacy of the audio.
- Multi-Shot Continuity: On Higgsfield, native audio continues seamlessly across cuts. A character can start a sentence in a wide shot and finish it in a close-up without any audio jumps. This is a massive leap forward for storytelling, as it allows for cinematic editing while maintaining a coherent soundscape.
Global Reach Through Native Lip-Sync
Native audio is the secret weapon for global content. It allows creators to reach international audiences without the badly dubbed feel of traditional translation. In a globalized economy, the ability to localize content instantly is an incredible competitive advantage.
- Multilingual Authenticity: Models like Seedance 2.0 support phoneme-level lip-sync in over eight languages, including English, Chinese, French, and German. The mouth movements are generated to match the specific linguistic nuances of each language.
- Preserved Tone: The speaker’s original tone, rhythm, and emotional weight stay consistent across different languages. If the original performance was sarcastic, the translated version carries that same sarcasm natively in the new language.
- One-Click Localization: A single marketing campaign can be ready for ten global markets in minutes. This allows brands to maintain a consistent global voice while being deeply local in their delivery.
The Rise of One-Take Cinematic Styles
Native audio enables more complex storytelling techniques that were previously impossible for AI. It gives creators the tools to experiment with styles that were once considered too technically difficult or expensive to pull off with generative tools.
- Continuous Soundscapes: Long-take tracking shots can now have continuous, evolving audio that reacts to everything the camera passes. As the camera moves from an indoor hallway to an outdoor street, the sound profile shifts in real-time.
- Rhythmic Ad Editing: Creators can feed the AI a specific music beat, and the model will generate visual hits and camera movements that land perfectly on the rhythm. This is particularly useful for high-energy social media content like TikToks or Reels.
- Atmospheric Immersion: The AI can generate the specific air and background texture of a scene, making it feel like a real film rather than a digital generation. This room tone is what often separates amateur work from professional cinema.
The Strategic Shift for Creators in 2026
The shift to native audio means creators are moving from being technicians who stitch files together to directors who shape entire sensory experiences. The focus is no longer on the how of production, but on the what of the story.
A 2026 technical report on the MOVA architecture explains that moving away from cascaded pipelines (separate video and audio tools) is essential for reducing errors and maintaining high quality. Unified architectures like Seedance 2.0 ensure that the audio and video remain in a symbiotic loop.
By utilizing these unified tools on Higgsfield, the barrier between a creative idea and a finished, professional-grade production has essentially vanished. Creators are now free to iterate, experiment, and fail quickly, which is the cornerstone of great art.
Conclusion: The Unified Future of Digital Reality
The conclusion is clear: we have reached the end of the silent era. Native audio is not just a feature; it is the fundamental requirement for the next generation of digital content. In 2026, the standard for a good AI video has moved beyond how it looks. It is now about how it feels, and you cannot have feeling without sound.
By moving away from fragmented workflows and embracing unified multimodal systems, creators are unlocking a level of realism that was previously unthinkable. The Higgsfield platform has made this professional-grade technology accessible to everyone, from solo influencers to enterprise-level agencies.
As we look toward the rest of the decade, the integration of audio and video will only become more seamless. We are moving toward a future where AI does not just generate clips, but creates entire living, breathing worlds. For the modern creator, the message is simple: stop making silent films. The future has a voice, and it is native.


